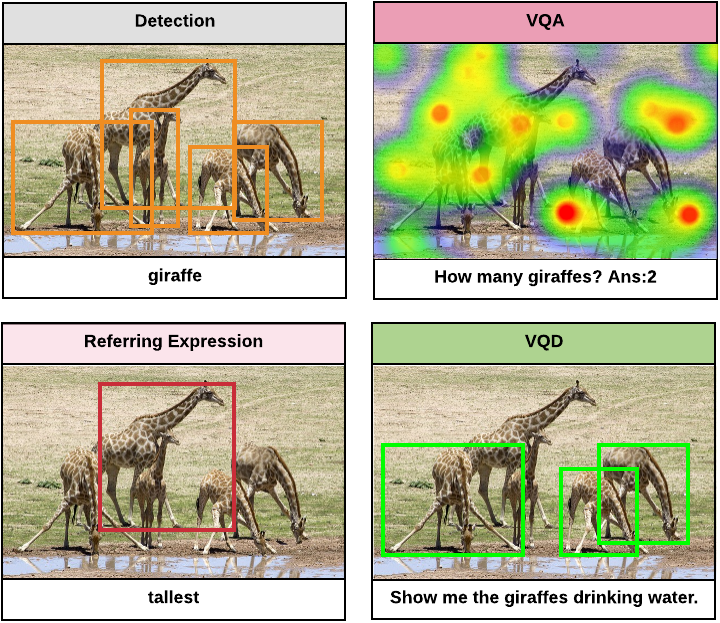
We introduce the Visual Query Detection (VQD) task in which given a query in natural language and an image the system must produce
0 - N boxes that satisfy that query. VQD is related to several other tasks in computer vision, but it captures abilities these other tasks ignore. Unlike object detection, VQD can deal with attributes and relations among objects in the scene. In VQA, often algorithms produce the right answers due to dataset bias without `looking' at relevant image regions. Referrring Expression Recognition (RER) datasets have short and often ambiguous prompts, and by having only a single box as an output, they make it easier to exploit dataset biases. VQD requires goal-directed object detection and outputting a variable number of boxes that answer a query.
We created
VQDv1, the first dataset for VQD. VQDv1 has three distinct query categories:
- Object Presence (e.g., `Show the dog in the image')
- Color Reasoning (e.g., `Which plate is white in color?')
- Positional Reasoning (e.g., `Show the cylinder behind the girl in the picture')
Some example images from our dataset are given below.

VQDv1 Stats
Compared to other dataset VQD has the
largest number of questions and the number of bounding boxes range from
0-15. In summary, it has
- 621K Questions:
- 391K Simple Questions
- 172K Color Questions
- 58K Positional Questions
- 123K Images


