Manoj Acharya
Machine Learning Researcher at SRI International
Email: manoj.acharya@sri.com, ma7583@rit.eduCV
Github

Machine Learning Researcher at SRI International
Email: manoj.acharya@sri.com, ma7583@rit.edu
|
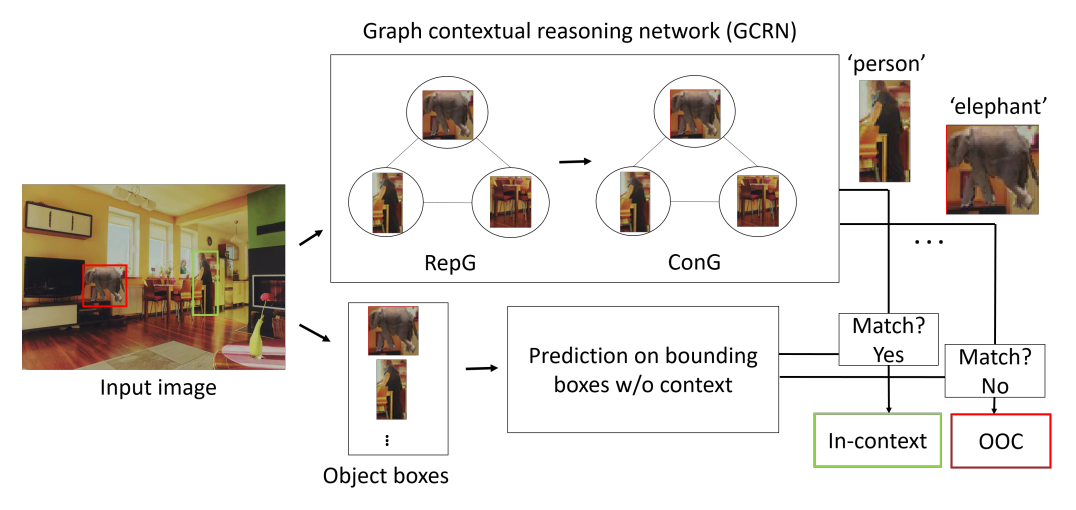
Detecting out-of-context objects using graph contextual reasoning network. Manoj Acharya, Anirban Roy, Kaushik Koneripalli, Susmit Jha, Christopher Kanan, Ajay Divakaran IJCAI-ECAI 2022
abstract /
bibtex /
code
video
This paper presents an approach to detect out-of-context (OOC) objects in an image. Given an image with a set of objects, our goal is to determine if an object is inconsistent with the scene context and detect the OOC object with a bounding box. In this work, we consider commonly explored contextual relations such as co-occurrence relations, the relative size of an object with respect to other objects, and the position of the object in the scene. We posit that contextual cues are useful to determine object labels for in-context objects and inconsistent context cues are detrimental to determining object labels for out-of-context objects. To realize this hypothesis, we propose a graph contextual reasoning network (GCRN) to detect OOC objects. GCRN consists of two separate graphs to predict object labels based on the contextual cues in the image: 1) a representation graph to learn object features based on the neighboring objects and 2) a context graph to explicitly capture contextual cues from the neighboring objects. GCRN explicitly captures the contextual cues to improve the detection of in-context objects and identify objects that violate contextual relations. In order to evaluate our approach, we create a large-scale dataset by adding OOC object instances to the COCO images. We also evaluate on recent OCD benchmark. Our results show that GCRN outperforms competitive baselines in detecting OOC objects and correctly detecting in-context objects. |
|
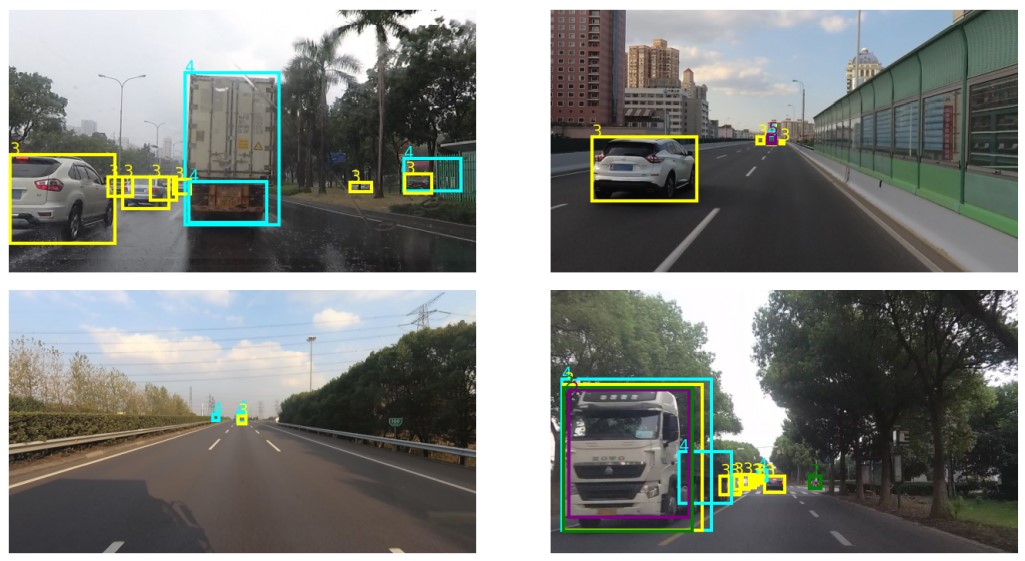
2nd Place Solution for SODA10M Challenge 2021 -- Continual Detection Track. Manoj Acharya, and Christopher Kanan ICCVW 2021
abstract /
bibtex /
In this technical report, we present our approaches for the continual object detection track of the SODA10M challenge. We adapt ResNet50-FPN as the baseline and try several improvements for the final submission model. We find that task-specific replay scheme, learning rate scheduling, model calibration, and using original image scale helps to improve performance for both large and small objects in images. Our team `hypertune28' secured the second position among 52 participants in the challenge. This work will be presented at the ICCV 2021 Workshop on Self-supervised Learning for Next-Generation Industry-level Autonomous Driving (SSLAD). |
|
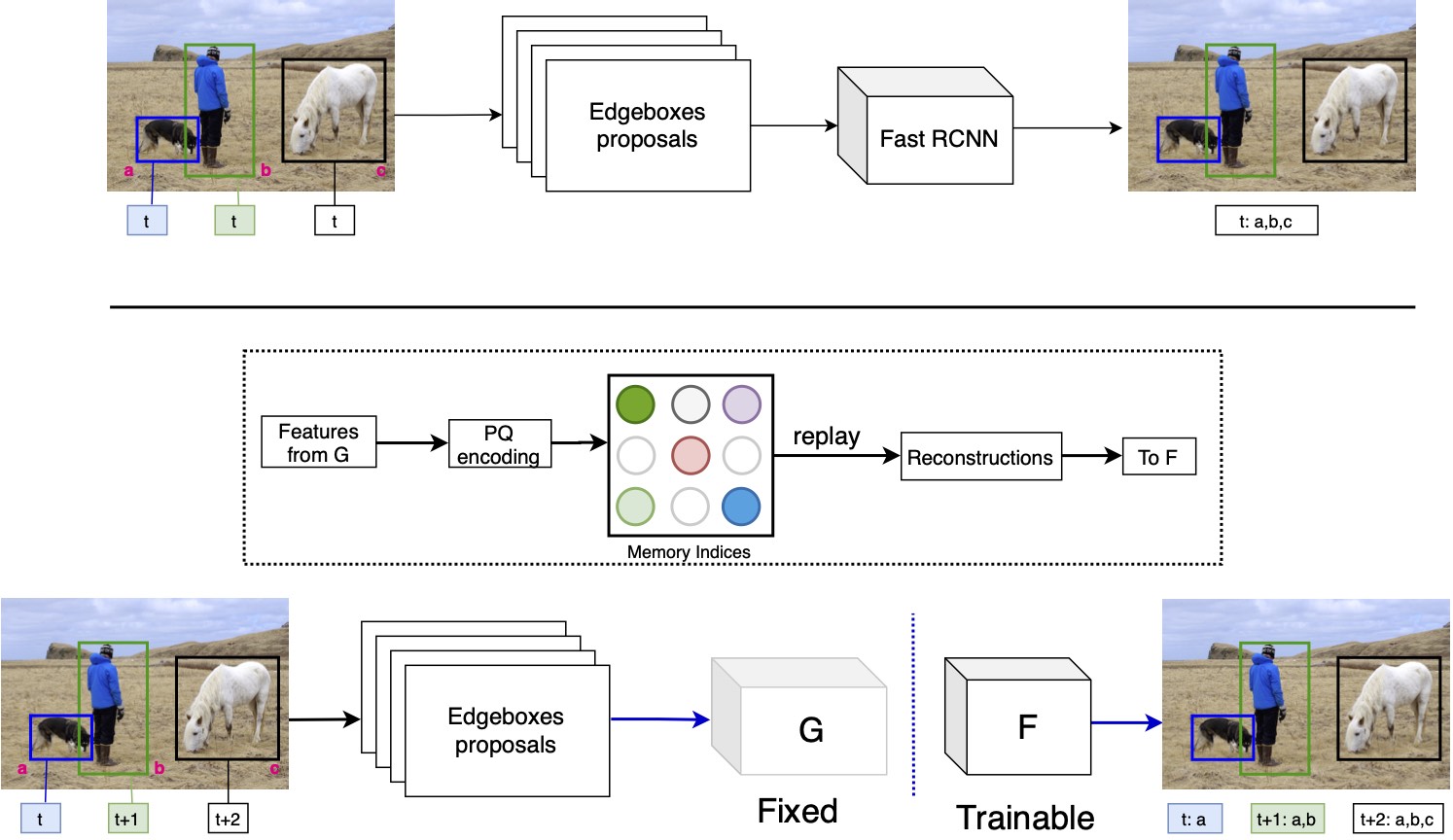
RODEO: Replay for Online Object Detection. Manoj Acharya, Tyler L. Hayes, and Christopher Kanan BMVC 2020
abstract /
bibtex /
code /
video
Humans can incrementally learn to do new visual detection tasks, which is a huge challenge for today's computer vision systems. Incrementally trained deep learning models lack backwards transfer to previously seen classes and suffer from a phenomenon known as ``catastrophic forgetting.'' In this paper, we pioneer online streaming learning for object detection, where an agent must learn examples one at a time with severe memory and computational constraints. In object detection, a system must output all bounding boxes for an image with the correct label. Unlike earlier work, the system described in this paper can learn how to do this task in an online manner with new classes being introduced over time. We achieve this capability by using a novel memory replay mechanism that replays entire scenes in an efficient manner. We achieve state-of-the-art results on both the PASCAL VOC 2007 and MS COCO datasets. |

|
REMIND Your Neural Network to Prevent Catastrophic Forgetting. Tyler L. Hayes*, Kushal Kafle*, Robik Shrestha*, Manoj Acharya, and Christopher Kanan ECCV 2020
abstract /
bibtex /
code
People learn throughout life. However, incrementally updating conventional neural networks leads to catastrophic forgetting. A common remedy is replay, which is inspired by how the brain consolidates memory. Replay involves fine-tuning a network on a mixture of new and old instances. While there is neuroscientific evidence that the brain replays compressed memories, existing methods for convolutional networks replay raw images. Here, we propose REMIND, a brain-inspired approach that enables efficient replay with compressed representations. REMIND is trained in an online manner, meaning it learns one example at a time, which is closer to how humans learn. Under the same constraints, REMIND outperforms other methods for incremental class learning on the ImageNet ILSVRC-2012 dataset. We probe REMIND's robustness to data ordering schemes known to induce catastrophic forgetting. We demonstrate REMIND's generality by pioneering online learning for Visual Question Answering (VQA). |
|
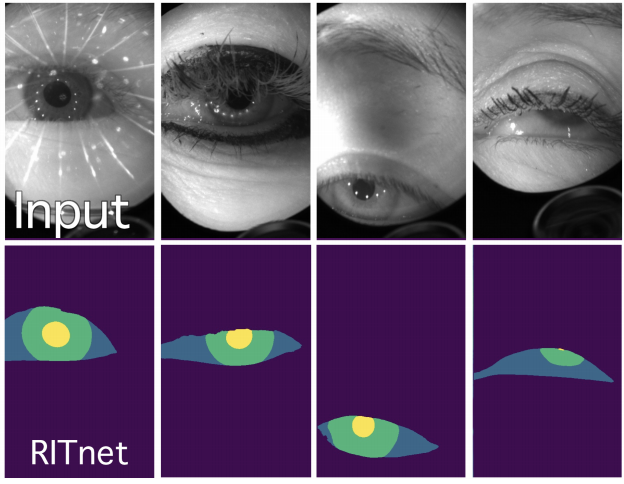
RITnet: Real-time Semantic Segmentation of the Eye for Gaze Tracking. Aayush Chaudhary*, Rakshit Kothari*,Manoj Acharya*, Shusil Dangi, Nitinraj Nair, Reynold Bailey, Christopher Kanan ,Gabriel Diaz, Jeff Pelz ICCVW 2019 (Competition Winner)
abstract /
bibtex /
code
Accurate eye segmentation can improve eye-gaze estimation and support interactive computing based on visual attention; however, existing eye segmentation methods suffer from issues such as person-dependent accuracy, lack of robustness, and an inability to be run in real-time. Here, we present the RITnet model, which is a deep neural network that combines U-Net and DenseNet. RITnet is under 1 MB and achieves 95.3% accuracy on the 2019 OpenEDS Semantic Segmentation challenge. Using a GeForce GTX 1080 Ti, RITnet tracks at > 300Hz, enabling real-time gaze tracking applications. Pre-trained models and source code are available this https URL. |
|
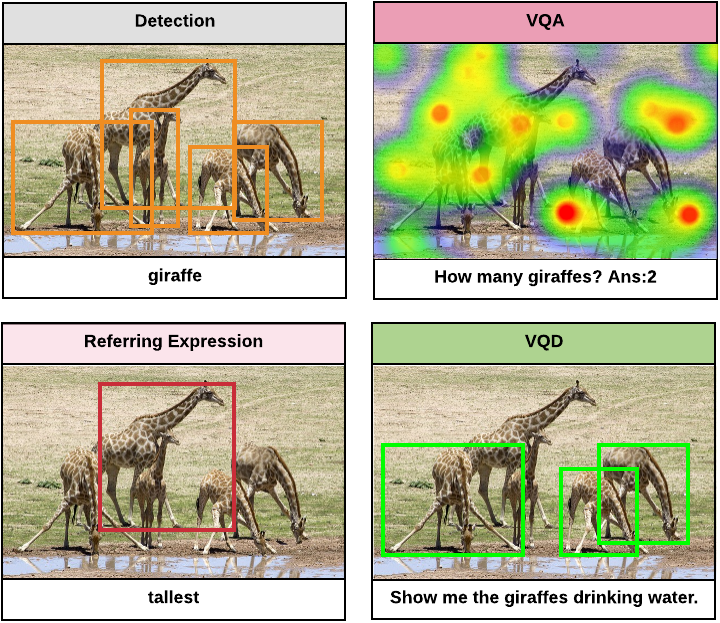
VQD: Visual Query Detection in Natural Scenes. Manoj Acharya , Karan Jariwala, Christopher Kanan NAACL 2019
abstract /
bibtex /
website
We propose Visual Query Detection (VQD), a new visual grounding task. In VQD, a system is guided by natural language to localize a variable number of objects in an image. VQD is related to visual referring expression recognition, where the task is to localize only one object. We describe the first dataset for VQD and we propose baseline algorithms that demonstrate the difficulty of the task compared to referring expression recognition. |

|
TallyQA: Answering Complex Counting Questions. Manoj Acharya , Kushal Kafle, Christopher Kanan AAAI 2019 (Spotlight Presentation)
abstract /
bibtex /
website /
code
Most counting questions in visual question answering (VQA) datasets are simple and require no more than object detection. Here, we study algorithms for complex counting questions that involve relationships between objects, attribute identification, reasoning, and more. To do this, we created TallyQA, the world's largest dataset for open-ended counting. We propose a new algorithm for counting that uses relation networks with region proposals. Our method lets relation networks be efficiently used with high-resolution imagery. It yields state-of-the-art results compared to baseline and recent systems on both TallyQA and the HowMany-QA benchmark. |